Abstract
Nowadays, NAND flash memory has been widely used as storage medium for embedded systems because of its small size, lightweight, shock resistance, power economic and high reliability. As its capacity increases and its price decreases, flash-memory-based SSDs (abbreviated Solid-state Driver) has also become an alternative of magnetic disk in enterprise computing environment. In addition, flash memory has the characteristics of not-in-place update and asymmetric I/O costs among read, write, and erase operations, in which the cost of write/erase operations is much higher than that of read operation. Hence, the buffer replacement algorithms in flash-based systems should take the asymmetric I/O costs into account. There are several solutions to this issue, such as LRU, CFLRU, APRA and AML. As we LRU policy is a basic cache replacement algorithm and page replacement algorithm. Thus we try to introduce the different variants algorithm of LRU used especially in flash memory.
Instruction
Toshiba company developed flash memory EEPROM (abbreviated electronically erasable programmable read-only memory). There are two types of flash memory, NOR and NAND. The names are two logic gates used in each flash memory because the two types of memory exhibits similar characteristics of the corresponding logic gates. Besides the different design of two type of flash memories, the most important difference between the NOR and NAND flash memory is the bus interface. NOR flash memory is connected to Address/Data bus like cache memory device as SRAM. NAND flash memory uses a multiplexed I/O interface with additional control inputs. NOR flash memory is a random access device appropriate for code storage application, while NAND flash is a sequential access device appropriate for mass storage application. NOR flash memory can be used to store code and execute code, but NAND flash memory can’t store code because code can’t be executed there. It must be loaded into DRAM and executed there. Table 1 describes the main differences between NOR and NAND flash memory.
| Property | NOR | NAND |
|---|---|---|
| Interface | Bus | I/O |
| Cell Size | Large | Small |
| Cell Cost | High | Low |
| Read Time | Fast | Slow |
| Program Time single Byte | Fast | Slow |
| Program Time multi Byte | Slow | Fast |
| Erase Time | Slow | Fast |
| Power consumption | High | Low, but requires additional RAM |
| Can execute code | Yes | No, but newer chips can execute a small loader out of the first page |
| Bit twiddling | nearly unrestricted | 1-3 times, also known as “partial page program restriction” |
| Bad blocks at ship time | No | Allowed |
In addition, the characteristics of flash memory are significantly different from disks. First, the seek time of disk is very high because of numerous I/O activities. Second, flash memory has asymmetric read and write operation because the performance and energy consumption. Third, flash memory does not support in-place update because the write operation to the same page can’t be finished before the page is erased. Therefore, as the number of write operations is increasing so is the number of erase operations. When we consider the erase operations with write operations, the performance of a flash writing operation costs more than 8 times higher than flash read operation [2].
The operating system of embedded storage of most mobile devices has much more chances to optimize I/O subsystem to use particular features based on the characteristics of flash memory. The operating system can reduce the number of write and erase operations using the kernel-level information, and finally increase the performance. Most operating systems are customized for disk-based system and their replacement algorithms only concern the number of cache hits. But the operating system used for flash memory should consider different read and write cost when they replace pages. In this paper, we propose different replacement algorithms of flash memory, CFLRU, etc., and intend to compare the performance of these different replacement algorithms.
LRU Replacement Algorithm
LRU (abbreviated least recently used) has been frequently used for memory replacement algorithm, but this is not to say all the page lists are strictly maintained in LRU order when it used in operating system. In this section we intend to introduce the page replacement policy based on LRU replacement algorithm in Linux kernel. First, Virtual memory uses page cache to back up the data frequently referenced in the disk. When the page cache is full (see Fig. 1), the cache space is shrunk by selecting some less active pages and swapping them out the cache called page reclaiming. Thus we will focus on how the cache decides which pages to reclaim and how to maintain the least recently used pages swapping out of the cache space first.
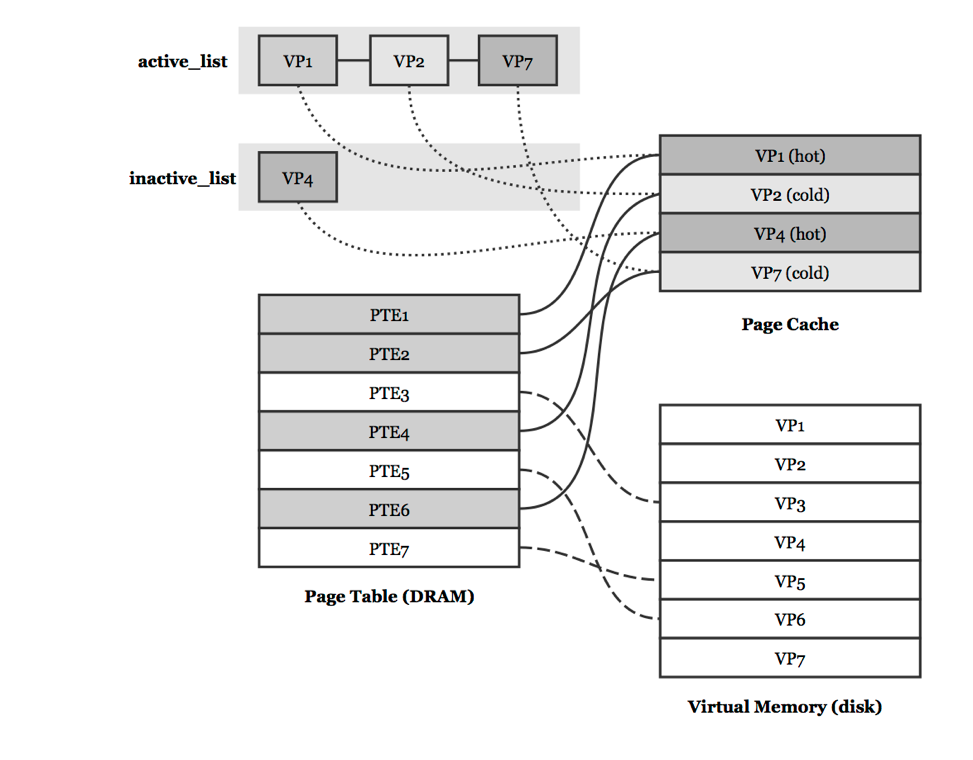
When a page in virtual address is accessed but not exists in physical memory the page faults are triggered. The page faults instruct the Linux kernel to read the missing data from the swap area. After writing back the data to the physical memory, the swap policy determines which pages can be swapped out of the physical memory without hitting the operating system performance. First, The LRU in Linux kernel contains two LRU lists called the active_list and inactive_list in Figure 1. The former list includes the pages that have been accessed recently, while the latter includes the pages that have not been accessed for some time. Apparently, future pages should be store from the inactive list. Second, there are two methods in Linux kernel to help maintain a balance between the active and inactive lists, shrink_active_list() and shrink_inactive_list(). The former is essentially responsible for deciding which page swapped out and which are not, while the latter is responsible for removing inactive pages from the inactive_list and transferring them to shrink_page_list, which then reclaims the selected pages by issuing requests to backing stores to write data back in order to free space physical memory.
In addition, the pages in the LRU lists may be cold or hot regardless either they are in active_list or inactive_list. If a page is hot, it means the page has been recently referenced. The pages in the inactive_list should be moved to the active_list because they are recently used. The pages in the inactive_list thus are always the least recently used pages. The kernel designed two flags to mark the hot/cold state of pages, PG_active and PG_referenced [3]. If the former is set, the page is in active_list, and in inactive_list vice versa. If the latter is set, the page is hot, and cold otherwise.
As we known, the page cache is a data structures which contain pages that are backed up. Fault pages or anonymous pages may be cached in this structures. The principle for this cache is to eliminate unnecessary disk reads. Pages read from disk are stored in a page hash table which hashed the address in order to always search the table before the disk is accessed. When caches have been shrunk, pages are moved from active_list to inactive_list. Pages are move from the end of the active_list. If the PG_referenced flag is set, it means the page is still hot and put back at the top of the active_list. This is sometimes called rotating the list in (see Fig. 2). If the PG_referenced flag is cleared, it is moved to inactive_list and set the PG_referenced flag in order to move back to active_list if necessary. After moving pages to inactive_list, the kernel can reclaim the pages in this list. We don’t discuss the page reclaiming in this section because the paper mainly focuses on the page replacement algorithm.
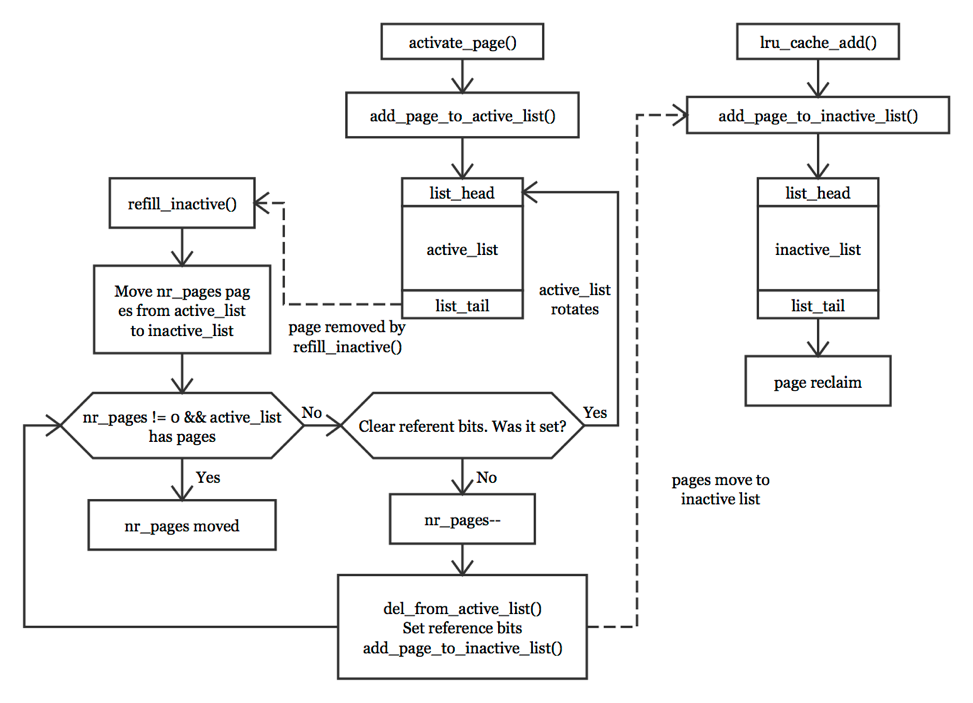
This LRU replacement algorithm implements is used in Linux kernel and works smoothly in a large number of machines. But it has some differences with machines using flash memory.
CFLRU Replacement Algorithm
As we mentioned before, flash memory cost more time on write operation than read operation. Thus when operating system reclaims pages we should minimize the number of write operations. There are two types of pages in page cache, dirty page and clean page. A dirty page contains different data from the data in flash memory thus its data must be written back to the memory before dropped. While A clean page contains the same copy of the original data in flash memory thus it can be just dropped from the page cache when it is evicted by the replacement algorithm. For this purpose, Park, Jung, Kang, Kim, & Lee (2006) propose a new replacement algorithm called CFLRU (abbreviated Clean-First LRU) [2]. CFLRU divides the LRU inactive_list into two regions as shown (see Fig. 3). The working region contains the of hot pages recently used, while the clean-first region contains pages which are candidates for reclaiming.
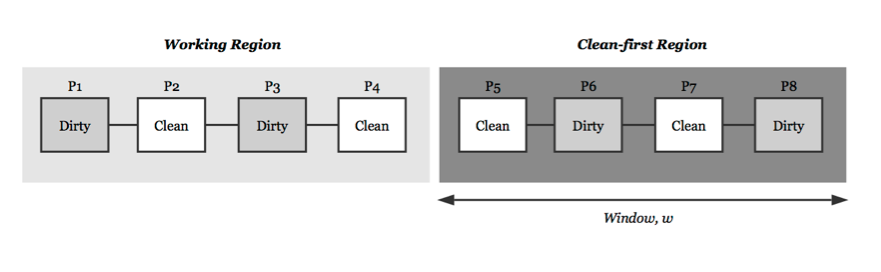
CFLRU first selects a clean page to reclaim in the clean-first region to reduce the cost of flash write operation. If there is no clean page in this region, a dirty page at the end of the inactive_list is reclaimed. For example, under the LRU replacement algorithm the last page in the inactive_list is reclaimed first. Therefore, the order for victim pages is P8, P7, P6, and P5, in Figure 3. However, under the CFLRU replacement algorithm, it is P7, P5, P8, and P6.
The size of the clean-first region is called widow size, w. The cache hit rate may fall dramatically because the window size is too large and the pages can be referenced future only in a small size of working region. If the window size reduces to one, CFLRU replacement algorithm will degenerates to a simple LRU replacement algorithm. Thus, Park et al. devise two methods to deal with this problem, static-CFLRU and dynamic-CFLRU. Under static method, they investigate the proper window size of the clean-first region with static parameters by obtaining an average well-performed value from repetitive experiments. The dynamic method can properly adjust the window size based on the information collected from currently flash memory reading and writing. If the ration of write operation is more than the ratio of read operation, the method can enlarge the window size, and narrow vice versa. With the experiments, the dynamic-CFLRU performs well in contrast to static-CFLRU.
The implement of CFLRU is not difficult based on Linux kernel. As we mentioned before, the original Linux kernel selects the victim page in the inactive_list and swaps out it, but under CFLRU dirty pages are simply skipped and find next victim which is a clean page. If pages in the inactive_list are all dirty, the kernel just swapped out the last pages of the list. For the window size of the clean-first region in CFLRU, we can simply change the priority value of pages in the inactive_list. To adjust the widow size properly, the priority values of pages can be changed dynamically. Park et al. devise a kernel deamon periodically checks the read and write cost and compare with last replacement cost to decide whether to increase or reduce the priority values. The difference between the current cost and last cost must exceed a predefined threshold in order to avoid oscillation of the priority values.
Adaptive Page Replacement Algorithm
Shen, Jin, Song, & Lee (2006) propose the APRA (abbreviated Adaptive Page Replacement Algorithm), because Shen et al. find that the read hit ratio of CFLRU is extremely low under certain workloads involving mainly read requests and its predefined window size contributes to the performance only for certain applications [5]. To deal with these shortcomings, the APRA maintains two cache lists of length L, LRU list and ghost list (see Fig. 4). The first list maintains a window to search clean pages just like CFLRU. However, the size of window can vary from Wmin to Wmax while static-CFLRU has fixed window size. Different from dynamic-CFLRU, the size of window in APRA can indicate the extent to which the clean pages are evicted from the buffer. The second list is called ghost list because it doesn’t contain the content of pages and just have the metadata of the pages which have been swapped out of the LRU list. In another word, the ghost list consists of the referenced history of pages which have been existed in LRU list. Although dirty pages evicted from LRU list have been already written back to the flash memory, we still mark these pages as dirty pages in ghost list to indicate the write operations.
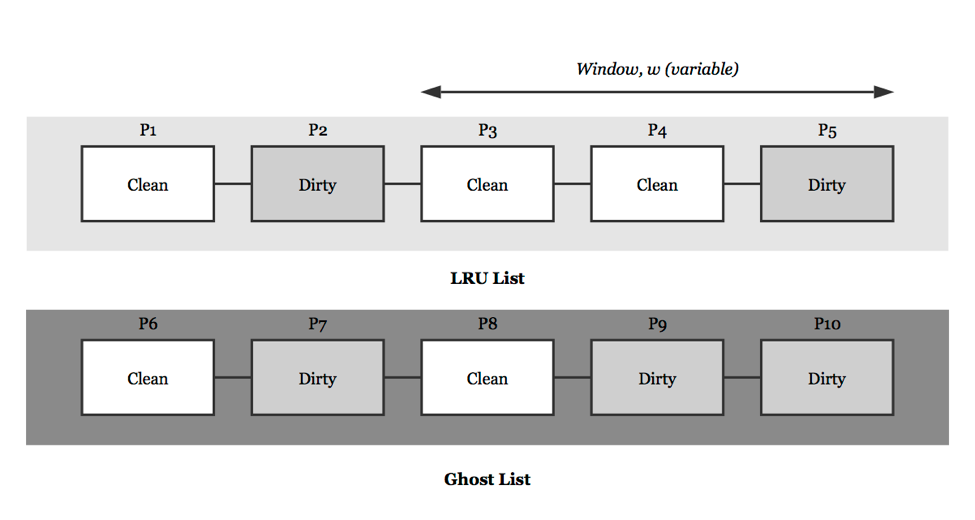
APRA can always modify the size of window w based on the information of the current workload since an appropriate value of w will dramatically increase the hit ratio. The algorithm indents to increase or decrease the window size in LRU list depending on whether the state of pages in ghost list is dirty or clean, because the hit information can be observed in ghost list. Therefore, if a hit happened on a dirty page in ghost list, we enlarger w, and a hit happened on a clean page in ghost list, we narrow w. The extent of w changing is also very important. Hence Shen et al. devise two parameters p and q to control the changing extent of revision, where p = L/w and q = 1/(1-w/L) control the revision rates depending on w. Thus, the smaller the w is, the larger the increment p will be. Similarly, the larger the w is, the larger the decrement q will be. Suppose a large of number requests mainly involving write operations from file system, APRA will increase the size of window to evict more clean pages in the LRU list. Likewise, when a large of number request mainly involving read operations, APRA will decrease the size of widow to achieve a high read hit performance.
AML Replacement Algorithm
Zhu, Dai, & Yang (2010) propose an improved LRU replacement algorithm called AML (abbreviated Adaptively Mixed List) algorithm, because Zhu et al. investigate that the evicting method of cold clean pages is inefficient. According to the page replacement policy, pages have to be evicted in the order of cold clean pages, hot clean pages, cold dirty pages, and hot dirty pages. Thus, AML replacement algorithm prefers to evict cold clean pages first and never chooses hot dirty pages as victims. In CFLRU algorithm, the clean pages are evicted regardless of cold or hot. However, the hot pages will be more likely to be referenced in the future than the cold pages. The cold pages thus must be evicted first to improve the hit ratio of page replacement in flash memory. To achieve the ideal results, AML maintains three LRU lists (see Fig. 5). The first list, LRU list, is just like CFLRU and APRA list with variable-size window. Cold clean list organizes all cold clean pages in the order of LRU list, and ghost list saves the metadata of swapped pages just like the ghost list in APRA, where it also doesn’t include any content of pages.
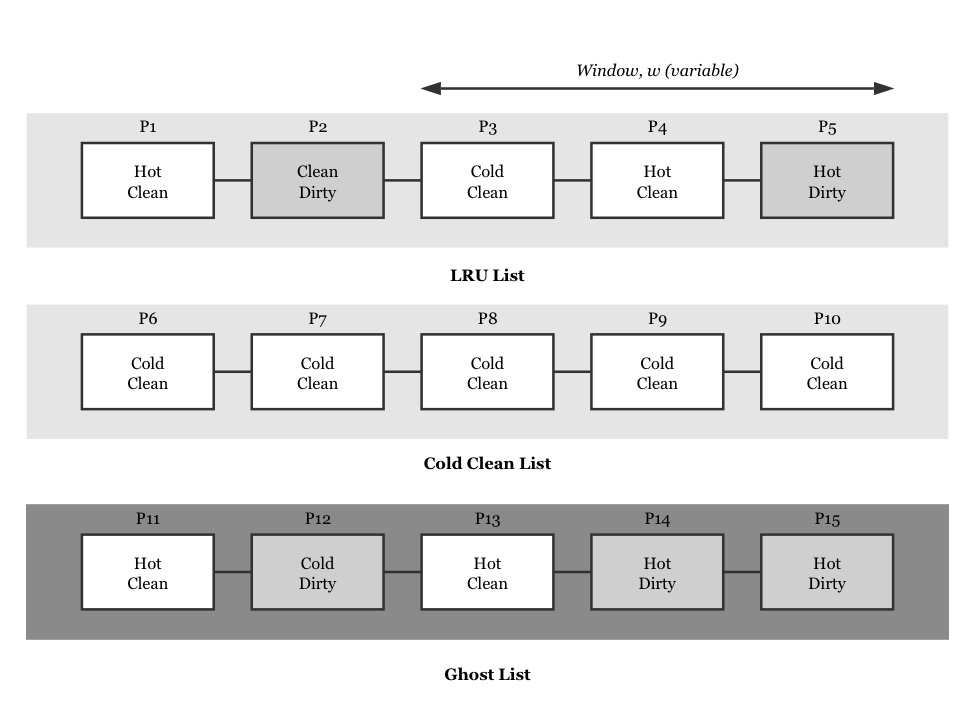
The AML algorithm improves CFLRU and APRA by maintaining a clean cold list, which can achieve the result that the clean cold pages can be first evicted. Zhu et al. devise a procedure to maintain the clean cold list which called cold-detection (see Fig. 6). In cold-detection, COOLMAX is an integer which is used to show the pages are the coldest. When the cold flag of a page reduces to zero, it shows that the page is hottest. For example, when COOLMAX is equal to 7, hot and cold can be divided into many levels from the coldest to the hottest (first hottest is 0, second hottest is 1, …, second coldest is 6, first coldest is 7). In addition, we can define which level is the boundary between cold and hot. When a page in AML lists is referenced, the procedure can move the cold clean pages to the clean cold list. If the referenced page is in the ghost list and it is a cold page (like P12 in fig. 5), moving it to the clean cold list and setting its cold flag as COOLMAX; If the referenced page is in the ghost list and it is a hot page (like P13 in fig. 5), moving it to the LRU list and its cold flag will be cleared to zero showing that it is a hot page; If the referenced page is in the cold clean list (like P9 in fig. 6), moving it to the LRU list and clearing its cold flag.
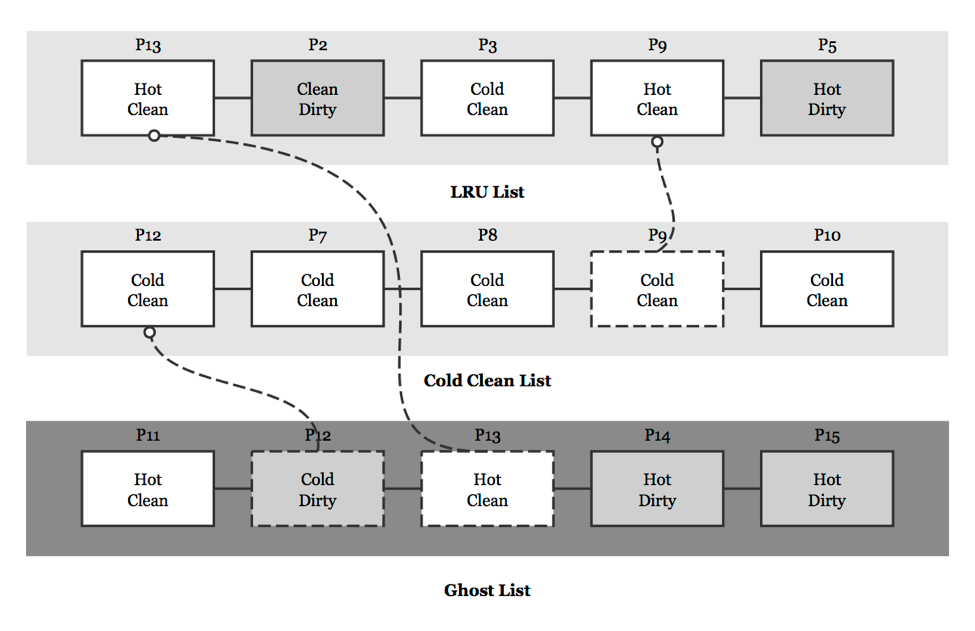
The eviction of AML algorithm is just like CFLRU algorithm but AML first concerns the pages in cold clean list. If the list is not empty, evicting the pages in the list. If the list is empty, evicting the pages in LRU list just like LRU list in CFLRU. When pages in LRU list are evicted, the ghost list adds pages contains the metadata of them, such as information of hot/cold and clean/dirty. Besides, the variable size of window in LRU list is just like APRA replacement algorithm, which changes the size that depends on the information in ghost list also maintained by AML algorithm.
Performance Evaluation
Zhu et al. perform a complete experiment includes LRU, CFLRU, APRA, AML and LRUWSR (which is a simple improve version of CFLRU). In the experiment, they use six kinds of workloads contain all the access pattern in Table 2. The total references are 1,000,000. The locality expression 80/20 means 80% of the total number of accesses operation are performed in 20% of the flash memory area. The write/read ration of 90/10 means that the write and read operations are 90% and 10% respectively.
| Type | Write/Read | Locality |
|---|---|---|
| T9182 | 90/10 | 80/20 |
| T5582 | 50/50 | 80/20 |
| T1982 | 10/90 | 80/20 |
| T9155 | 90/10 | 50/50 |
| T5555 | 50/50 | 50/50 |
| T1955 | 10/90 | 50/50 |
Figure 7 shows the hit ratios of the five replacement algorithms. The hit ratio of AML is almost equal to LRU. It is higher than other algorithms in most cases (see Fig. 6). Because AML prefers to evict the cold clean page first, and it delays eviction of hot page to keep high hit ratio. When the locality of data access is 50/50, the hit ratio of AML is pretty same as other three replacement algorithms. When locality is good and I/O access is write-dominant as 90/10, the hit ratio of AML is pretty same as that of APRA. On this condition, the major evicted pages are dirty pages, and clean pages are very few. Thus, the faster cold dirty pages are evicted, the higher is hit ratio.
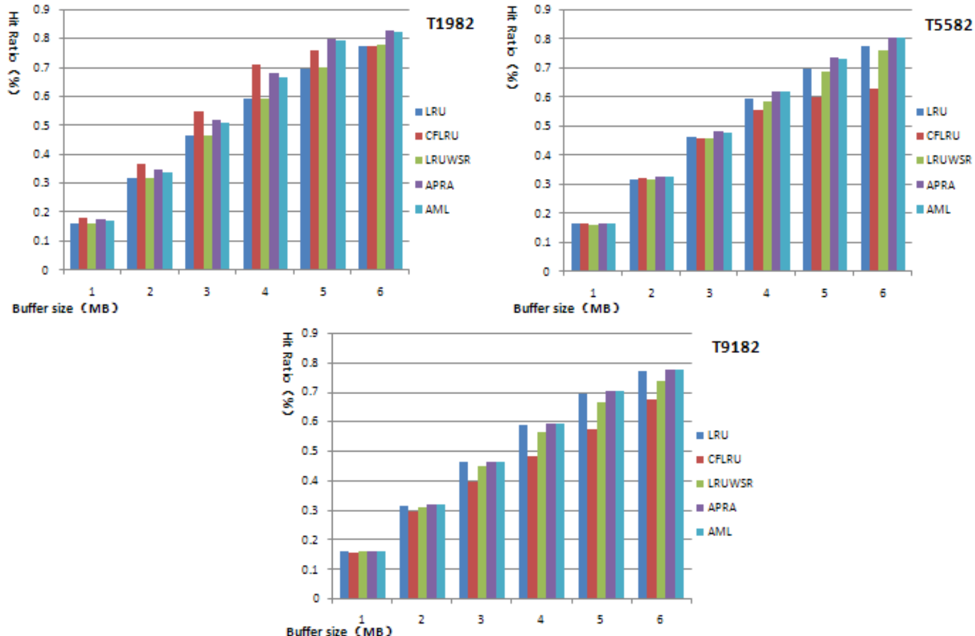
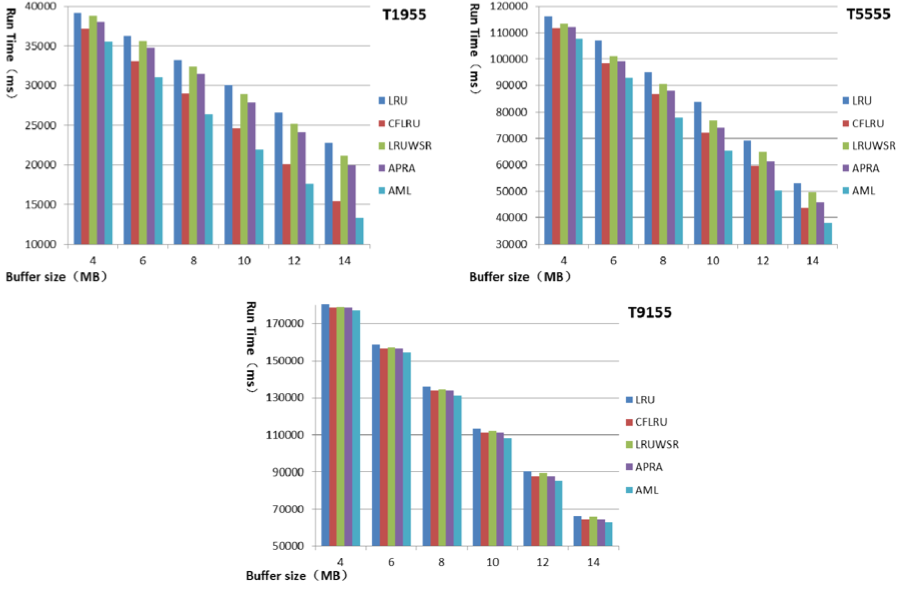
Figure 8 shows the number of pages written into flash memory. They got these results by counting the number of physical flush operations, and adding the number of dirty pages remaining in the buffer. They have known that a good algorithm not only keeps high hit ratio but also decreases the write counts effectively to reduce the replacement cost. AML is basically done both for various traces. When write/read ratio is smaller, the write count of AML is much less than other algorithms including APRA. It reduces the write count on average by 15% compared to APRA and by 10% compared to CFLRU. For write-most access pattern, the write count of AML is smaller than that of other algorithms. However, it is nearly equal to that of APRA.

Figure 9 shows the overall runtime of various replacement algorithms. Except LRU list AML maintain an additional ghost list. The space overhead of keeping ghost list is very small as the paper mentioned before. They only focus on the time overhead of these algorithm. Runtime is estimated as the sum of read, write latency and the time of erase operations. Runtime therefore reflects overall performance. The runtime is determined by hit ratio and write count. It is the standard to judge whether this algorithm is effective enough. The runtime of AML is reduced at most by 18% compared to APRA. Even if CFLRU has a good performance in the read-most applications, AML reduces the runtime on average by 14% compared to CFLRU.
Conclusion
In the LRU-based replacement algorithms of flash memory, we introduce the main LRU algorithm which is widely used in Linux kernel and many other operating systems. Then we mainly investigate three algorithm aiming to improve the traditional LRU replacement algorithm as we called LRU-based replacement algorithms. The first algorithm is CFLRU replacement algorithm. It changes the order of evicting pages in LRU within selecting clean pages first. The method can reduce the cost of write operations. The second algorithm is APRA, which adds ghost list to dynamically change the size of window in CFLRU algorithm. Because the performance of CFLRU may decrease dramatically when the I/O access is read-dominant. The last algorithm is AML replacement algorithm which adds a cold clean list to APRA. The cold clean pages can be evicted first within the cold-detection method, and this algorithm performs better than three other algorithms in different condition in flash memory.
Reference
[1] Memory Technology Device (MTD) Subsystem for Linux, http://www.linux-mtd.infradead.org/doc/nand.html/.
[2] Park, S. Y., Jung, D., Kang, J. U., Kim, J. S., & Lee, J. (2006, October). CFLRU: a replacement algorithm for flash memory. In Proceedings of the 2006 international conference on Compilers, architecture and synthesis for embedded systems (pp. 234-241). ACM.
[3] Bovet, D. P., & Cesati, M. (2005). Page Frame Reclaiming, Understanding the Linux Kernel, Third Edition (pp. 676-737). O’Reilly Media, Inc.
[4] Page Frame Reclamation, https://www.kernel.org/doc/gorman/html/understand/understand013.html.
[5] Shen, B., Jin, X., Song, Y. H., & Lee, S. S. (2009). APRA: adaptive page replacement algorithm for NAND flash memory storages. In Computer Science-Technology and Applications, 2009. IFCSTA’09. International Forum on (Vol. 1, pp. 11-14). IEEE.
[6] Zhu, H., Dai, H., & Yan, Y. (2010, December). AML: a novel page replacement algorithm for Solid State Disks. In Computational Intelligence and Software Engineering (CiSE), 2010 International Conference on (pp. 1-6). IEEE.